
Typical Exif Data
Date: 2014 F Jun 14 Source: wikipedia Exif
Note that the above sample of Exif data was captured in 2003. That was 11 years ago.
The author is David KC Cole, the WebMaster of various webpages. His first webpage was his personal webpage named ColeDavid.com. When he first started creating that webpage, he learned the following truths:
Thirty years ago, who would have predicted the following developments:
Discussion More and more of our "Images, Articles and Pages" include images. The sources of images are:
Typical Exif DataDate: 2014 F Jun 14 Source: wikipedia Exif
Note that the above sample of Exif data was captured in 2003. That was 11 years ago.
IPTC Data
The IPTC method stores caption information within the photo itself, in JPEG photo formats. The IPTC method was created for foreign journalists who occassionally found that their caption information was paired up with the wrong photo as the photos were transferred to the publisher. The IPTC mechanism was not embraced by the whole publishing community. However,IrfanView and Picasa do use IPTC, to varying degrees. Hopefully, all programs which edit JPG photos will retain any accompanying IPTC data. As I find other photo editting programs that use IPTC, I will include them in this article.
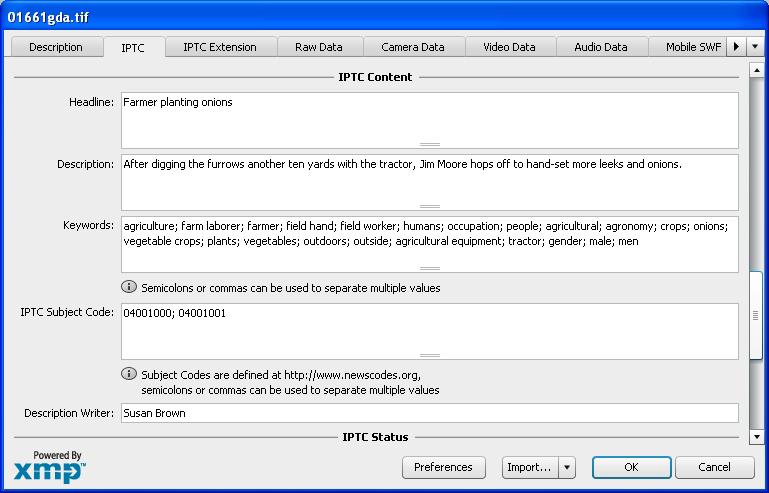
Typical IPTC DataDate: 2014 F Jun 14 Source: IPTC 2010 Standard
IPTC attributes
Note that the above format of IPTC data was captured in 2010. That was only 4 years ago. Many other attributes can also be embedded in JPG digital images, but not automatically by the camera, of course. The first IPTC standard was developed in the 1980s for use by journalists. The goal was to ensure that the captions were not assigned to the wrong images. More information is available at IPTC 2010 Standard. The free program named Irfanview can be used to insert and view IPTC attributes in JPEG images.
Today's IPTC attributes
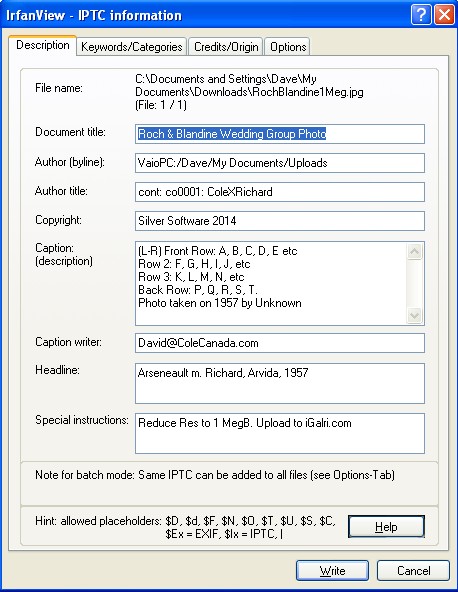
IrfanView IPTC FieldsDate: 2014 G Jul 12 Source: IrfanView Editor
IrfanView's IPTC fields
This example of IrfanView's IPTC data was captured in 2014. The data in each field is an example of how the author would use the fields to upload IPTC info to iGalri.com. To date, the iGalri.com site ignores the IPTC data fields in the photos that are uploaded.
Picasa's IPTC attributes
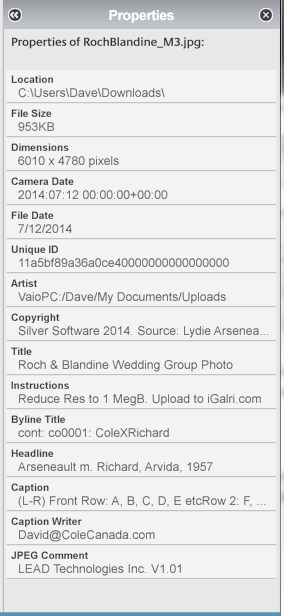
Picasa IPTC FieldsDate: 2014 G Jul 12 Source: Picasa Gallery for Windows
Picasa's IPTC fields
This example of Picasa's IPTC data was captured in 2014. The data in each field shows how Picasa displays the data that was entered using Irfanview (above). Picasa allows the user to only edit the Caption (Description) data but no other fields, even though they are displayed. Picasa displays the above fielded information to the right of the photo. Picasa displays the full IPTC caption (description) underneath the photo, where it can be editted. the image below shows how Picasa displays the photo, with the IPTC fields to the right, with the IPTC caption (description) below the photo.

Picasa Photo Display
Image Attributes used by David KC Cole
The author has found that the following main attributes were important for images used by his web pages such as www.iGalri.com. Users of this web site can use their iPad to take the snapshot, verbally add the caption, and upload the information to the iGalri.com database. Users who have iPads can verbally specify their search criteria to request and view all relevant captioned images.Author's Image Attributes
Of course, all the Exif and IPTC information is still available in the actual digital images. Being available, it could be used to populate future image attribute fields (columns). Submitters of captioned images are requested to include major attributes such as names of subjects, location and source in the caption information.- object (name of image)
- email address (of submitter)
- datePosted (when image/caption was added/updated)
- pathName (where image came from...if on a local drive)
- urlName (where image was found...if on the web)
- verbage (caption information...in html)
- imgHeight (in pixels)
- imgWidth (in pixels)
- container (repository on server i.e. a gallery)
- site (where image is displayed)
- status (of image.. eg. deleted)
- isPublic (viewable by all i.e. NOT private)
- other minor attributes
Definitions of Images, Articles and Pages
Image Definition An Image is a JPG type of image that is stored in the ePC (ePhotoCaption) group of web pages. Images are used (i.e. presented) here in four ways:
Presentation of Images
- Captioned Image stored in an ePC gallery
- Image used in a ePC Page (i.e. an HTML page within a web site)
- Image used in an ePC Article
- Image whose primary usage is by the public, not by ePC
Page Definition Article Definition
Image Usage
Captioned Image stored in an ePC gallery
A Captioned Image that is stored in an ePC gallery is always for private (not public) viewing. Such images might be flagged for public viewing. Therefore this images must NOT be stored in web pages where they are available to the public.
Image used in a ePC Page (i.e. an HTML page within a web site)
Most of these images are used directly by an ePC web site. These are usually stored in a folder named `images` off the root of the web site. This makes them easy to locate but it also makes it impossible to store two different images that have the same name. This is not usually a problem for the WebMaster of the web site.
However, sometimes an html link to a non-ePC website is so important that the disappearance of the non-ePC linked page must be avoided. In this case, a copy of the non-ePC linked page is made. A copied page should not be included in an ePC web site, mainly because of the image references. These are references to images that must also be copied from the non-ePC web site. So the non-ePC images and non-ePC html pages must be stored somewhere else, but in a public area, so that the ePC web sites can access them. Therefore these non-ePC images and pages are stored in a unique folder under folder `a` that is off of the root of `ePhotoCaption.com`. These non-ePC copied images can be housed in folders that bear the same relationship to the copied html pages. This is necessary to minimize the editting of non-ePC html pages; editting that must be done because they are no longer in their previous environment.
Image used in an ePC Article
An ePC Article is simply an html page written by the ePC WebMaster. An ePC Article and its images are always public. So the ePC article is stored like an html page from a non-ePC html page. Therefore this non-ePC images and pages are stored in a unique folder under folder `a` that is off of the root of ePhotoCaption.com. The unique folders off the folder named `a` are uniquely numbered beginning with number 1. Occassionally, a higher number will be used, if it corresponds to a number in the non-ePC web site.
Image whose primary usage is by the public, not by ePC
Sometimes an image must be viewable by the public in non-ePC Web Sites. An example of this is in the Post-Em notes offered by World Connect. An example of a Post-Em Note can be seen for James Edwin COLE in WorldConnect. To see a Post-em Note at this URL, click on an html link named `View Post-em`. For example an image of the person might need to be referenced. Since such images are NOT necessarily referenced by any ePC html pages, they must be placed in another folder. Such images are stored in a folder named `img` off the root of `ePhotoCaption.com`.
Review
All images uploaded to the server by an ePC html page or by the ePC WebMaster are stored in one of the following places:ePC Image Repositories
It is important to know where all of the ePC images are stored. This is because it is sometimes necessary to search for a specific image. This is especially true when an image must be replaced by a more recent (or more correct) image. Sometimes when an image must be referenced a second time within the ePC system, its exact location must be found. Another reason is when ePC images are being moved to a new container (gallery).- in an ePC web Site (other than ePhotoCaption)
- in an ePC container (gallery) folder
- in a folder under folder `a` off the root of ePhotoCaption.com
- in a folder `img` off the root of ePhotocaption.com